Характеристики и факты о M1
Напоследок несколько важных характеристик и дополнительная информация о процессоре Apple M1:
- Apple не называла тактовые частоты M1, но тесты показывают значения до 3.2 ГГц. Это частота четырёх высокопроизводительных ядер. Энергоэффективные ядра должны работать на заметно меньших тактовых частотах;
- У Apple M1 четыре мощных ядра и четыре энергоэффективных. Разница между ними очень существенна. Подобный подход сейчас повсеместно используется в мобильных ARM-процессорах. В то же время обычные процессоры Intel и AMD имеют равнозначные по мощности ядра;
![]()
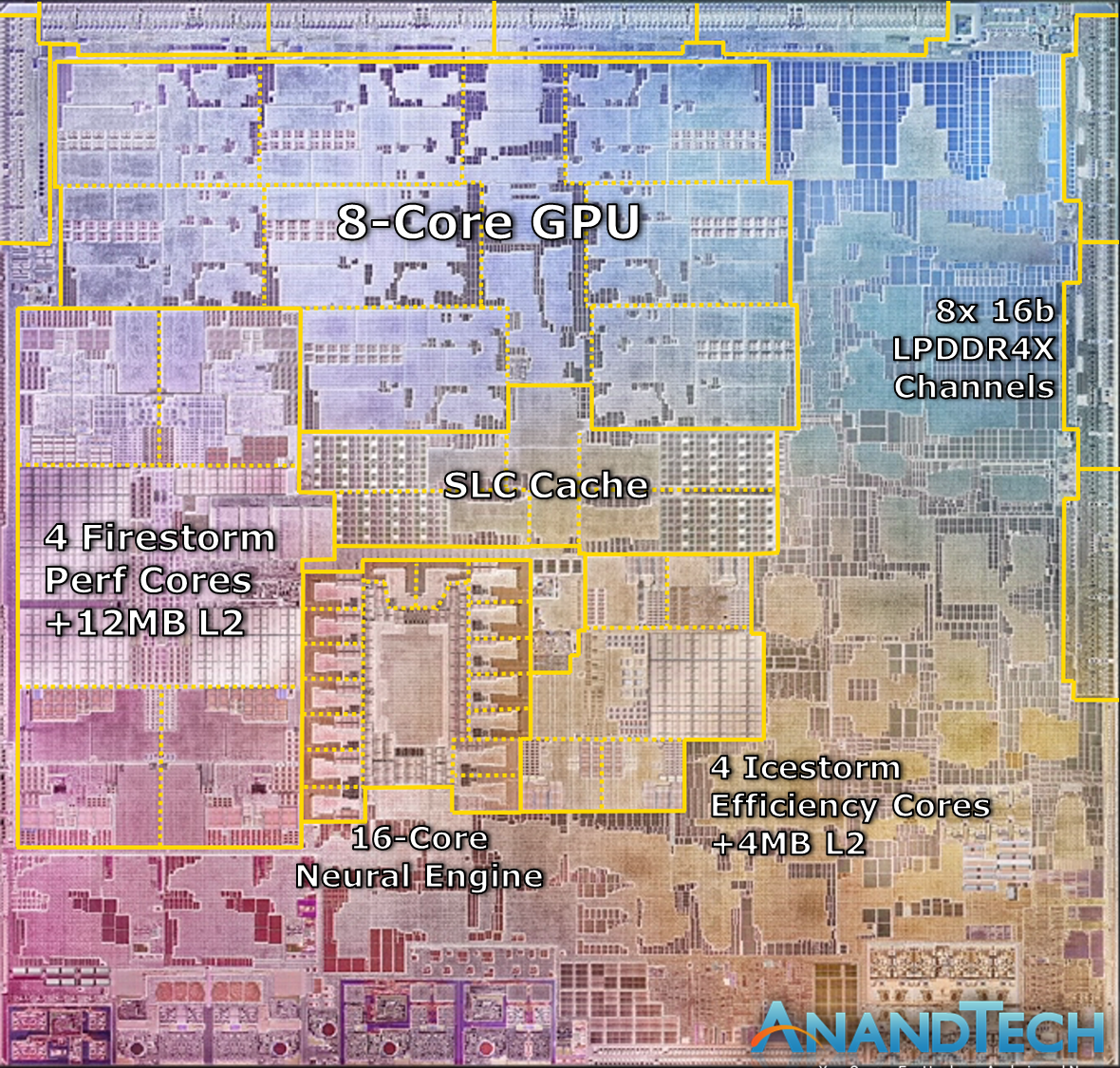
Ключевые характеристики M1 включают в себя производство по 5 нм нормам, 16 миллиардов транзисторов, отдельной сопроцессор обработки изображений, встроенную память и рекордное для индустрии соотношение производительности на ватт
- Использование ядер двух типов позволяет M1 расходовать ещё меньше энергии. Мощные ядра задействуются далеко не во всех задачах, а только тогда, когда она действительно нужны;
- В отличии от процессоров Intel и AMD, что полагаются на внешнюю оперативную память, у M1 «оперативка» внутренняя. Она находится внутри самого чипа, что несёт ряд существенных преимуществ в скорости работы. Apple называет такую память объединённой;
- Технически объединённая память в Apple M1 – это LPDDR4X, работающая на частоте 3733 МГц. При этом традиционная для любых процессоров кэш-память у M1, разумеется, тоже есть;
![]()
Помимо новой объединённой памяти M1 может удваивать скорость работы с SSD накопителем. Благодарить за это стоит отдельные контроллеры и подсистемы работы с памятью, существенно отличающиеся от тех, что использует в своих процессорах Intel
- В M1 16 миллиардов транзисторов против 11.8 млрд. в Apple A14, применяемом в новейших iPhone 12 и iPad;
- M1 производится по передовому 5 нм техпроцессу. Основная часть процессор Intel всё ещё основывается на почётном в плане возраста 14 нм техпроцессе, а наиболее актуальные процессоры AMD используют 7 нм технологии.
Вопрос №2: что с совместимостью с VMWare vSphere
Поскольку для AMD EPYC родной средой обитания являются «облака», все cloud-операционные системы поддерживают эти процессоры без нареканий и без ограничений. И здесь недостаточно просто сказать, что оно «запускается и работает». В отличие от Xeon-ов, процессоры EPYC используют чиплетную компоновку. В случае с первым поколением (серия 7001) на общем корпусе CPU имеются четыре отдельных чипа со своими ядрами и контроллером памяти и может произойти такая ситуация, когда виртуалка использует вычислительные ядра, принадлежащие одному NUMA-домену, а данные лежат в планках памяти, подключённых к NUMA-домену другого чипа, что вызывает лишнюю нагрузку на шину внутри CPU. Поэтому производителям ПО приходится оптимизировать свой код под особенности архитектуры. В, частности, в VMWare научились избегать таких перекосов в распределении ресурсов для виртуальных машин, и если вас интересуют подробности, рекомендую почитать эту статью. К счастью, в EPYC 2 на ядре Rome этих тонкостей компоновки ввиду особенностей компоновки нет, и каждый физический процессор можно инициализировать как единый NUMA-домен.
У тех, кто начинает интересоваться процессорами AMD часто возникают вопросы: а как EPYC будет взаимодействовать с продукцией конкурентов в области виртуализации? Ведь в области машинного обучения пока что безраздельно властвует Nvidia, а в сетевых коммуникациях — Intel и Mellanox, который нынче часть Nvidia. Хочу привести один скриншот, на котором указаны устройства, доступные для проброса в среду виртуальной машины, минуя гипервизор. Учитывая, что AMD EPYC Rome имеет 128 линий PCI Express 4.0, вы можете устанавливать 8 видеокарт в сервер и пробрасывать их в 8 виртуальных машин для ускорения работы Tensorflow или других пакетов машинного обучения.
Давайте сделаем небольшое лирическое отступление и настроим наш мини-ЦОД для нужд машинного обучения с видеокартами Nvidia P106-090, не имеющими видеовыходов и созданными специально для GPU-вычислений. И пусть злые языки скажут, что это «майнинговый огрызок», для меня это «мини-тесла», прекрасно справляющаяся с небольшими моделями в Tensorflow. Собирая небольшую рабочую станцию для машинного обучения, установив в неё десктопные видеокарты, вы можете заметить, что виртуалка с одной видеокартой запускается прекрасно, но чтобы вся эта конструкция заработала с двумя и более GPU, не предназначенными для работы в ЦОД, надо изменить метод инициализации PCI-E устройства в конфигурационном файле VMware ESXi. Включаем доступ к хосту по SSH, подключаемся под аккаунтом root
и в открывшемся файле в конце находим
и прописываем (вместо ffff будут ваши ID устройства)
После чего перегружаем хост, добавляем видюхи в гостевую операционную систему и включаем её. Устанавливаем/запускаем Jupyter для удалённого доступа «а-ля Google Colab», и убеждаемся, что обучение новой модели запущено на двух GPU.
Когда-то мне нужно было оперативно посчитать 3 модели, и я запускал 3 виртуалки Ubuntu, пробросив в каждую по одному GPU, и соответственно на одном физическом сервере одновременно считал три модели, чего без виртуализации с десктопными видеокартами никак не сделаешь. Только представьте себе: под одну задачу вы можете использовать виртуалку с 8 GPU, а под другую — 8 виртуалок, каждая из которых имеет 1 GPU. Но не стоит выбирать игровые видеокарты вместо профессиональных, ведь после того, как мы изменили метод инициализации на bridge, как только вы выключите гостевую ОС Ubuntu с проброшенными видеокартами, повторно она уже не запустится до рестарта гипервизора. Так что для дома/офиса такое решение ещё терпимо, а для Cloud-ЦОД с высокими требованиями к Uptime — уже нет.
Но это не все приятные сюрпризы: поскольку AMD EPYC — это SoC, ему не нужен южный мост, и производитель делегирует процессору такие приятные функции, как проброс в виртуалку SATA контроллера. Пожалуйста: здесь их два, и один вы можете оставить для гипервизора, а другой отдать виртуальному программному хранилищу данных.
К сожалению я не могу показать на живом примере работу SR-IOV, и для этого есть причина. Я оставлю эту боль «на потом» и изолью душу дальше по тексту. Эта функция позволяет пробросить физически одно устройство, такое как сетевую карту сразу в несколько виртуальных машин, например, Intel X520-DA2 позволяет делить один сетевой порт на 16 устройств, а Intel X550 — на 64 устройства. Вы можете физически пробросить один адаптер в одну виртуалку несколько раз для того, чтобы пошаманить с несколькими VLAN-ами… Но как-то эта возможность не сильно находит применение даже в cloud-средах.
M1 в сравнении с процессорами Intel и AMD
В M1 8 ядер, четыре более мощных из них работают на частоте до 3.2 ГГц. Впрочем, сравнивать M1 с процессорами Intel и AMD напрямую – абсолютно неверно ввиду совершенно разных архитектур (M1 – ARM процессор). Поэтому обратимся к конкретным тестам. Начнём с официальный данных. Свои тесты Apple проводила в программе для обработки видео Final Cut Pro, а также в Xcode.
- M1 в 3.5 раза быстрее Intel Core i7-1060NG7 (4 ядра, 1.2 ГГц с ускорением до 3.8 ГГц);
- M1 в 2,8 раза быстрее Intel Core i7-8557U (4 ядра, 1.7 Гц с ускорением до 4.5 ГГц);
- M1 в 3 раза быстрее Intel Core i3-8100B (4 ядра, 3.6 ГГц).
![]()
M1 включает в себя 8 ядер центрального процессора, 8 графически ядер (блоков), а также 16 ядер для ускорения операций, связанных с машинным обучением
Все перечисленные процессоры Intel использовались в базовых версиях MacBook Air, MacBook Pro и Mac Mini прошлого поколения.
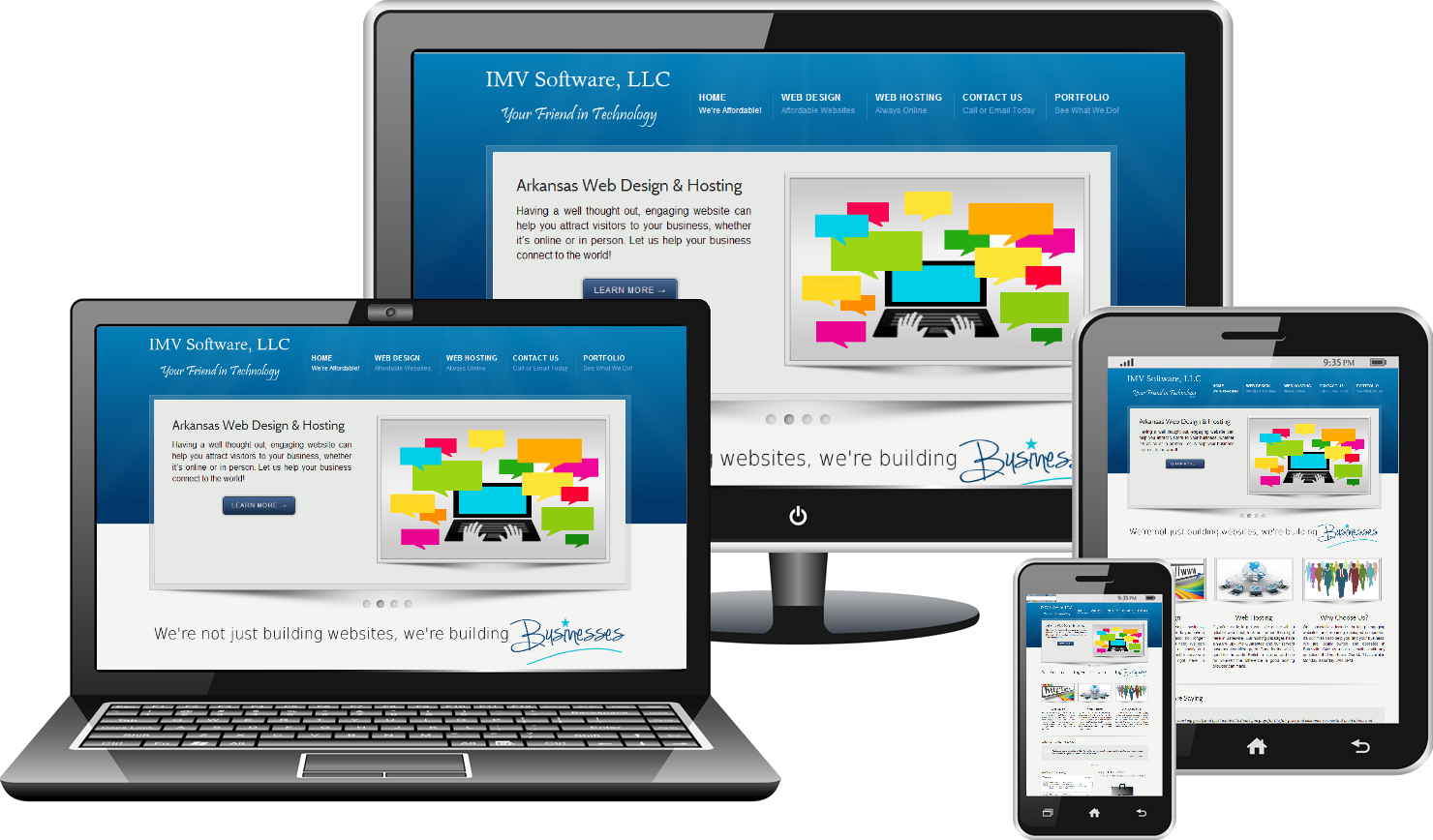
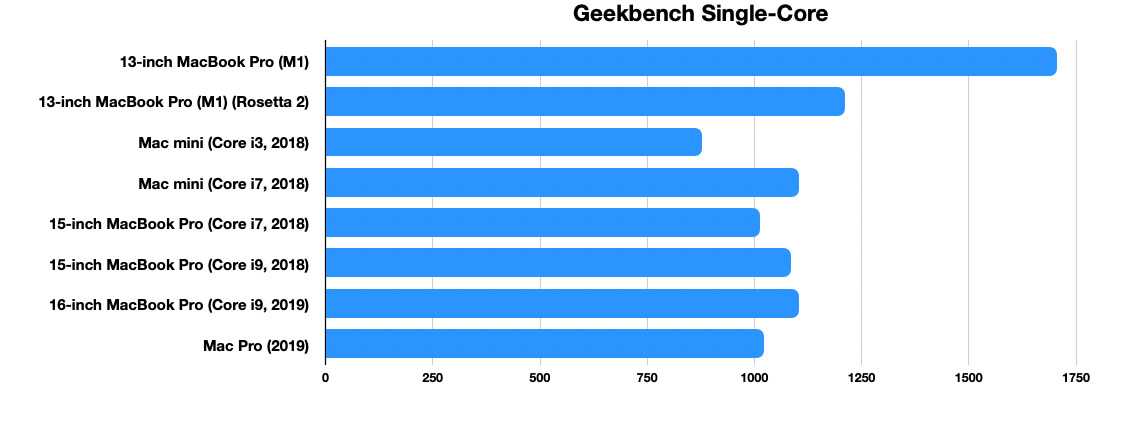
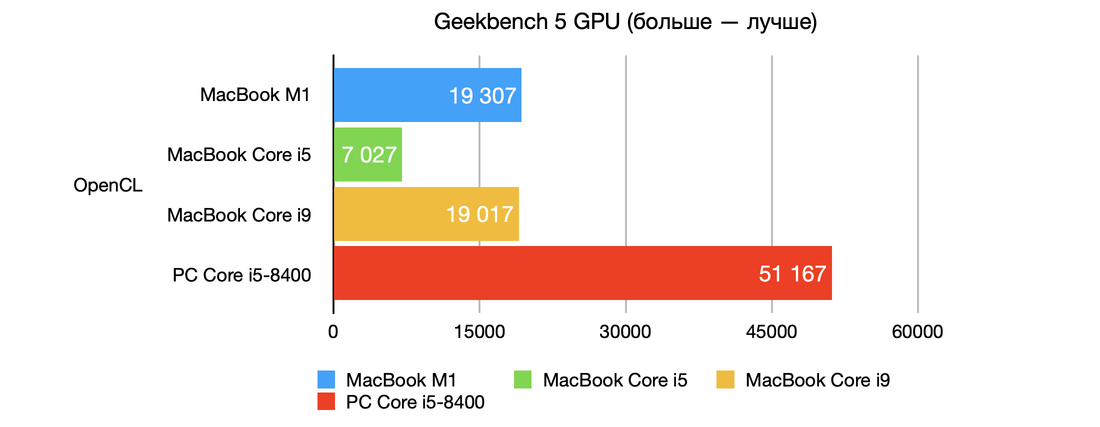
Впрочем, выше были приведены данные самой от Apple. Куда интереснее взглянуть на альтернативные тесты. Одним из таких является бенчмарк Geekbench 5, специализирующийся на оценке производительности ядер CPU.
Geekbench проверяет сразу два ключевых сценария: однопоточная производительность, где берётся одно наиболее мощное ядро, а также многопоточная производительность, в измерении которой участвуют уже все ядра. Результаты процессора M1 на фоне решений Intel и AMD здесь весьма впечатляют. Причём на этот раз сравнении идёт с топовыми моделями Core-i7/i9 и новейшими Ryzen.
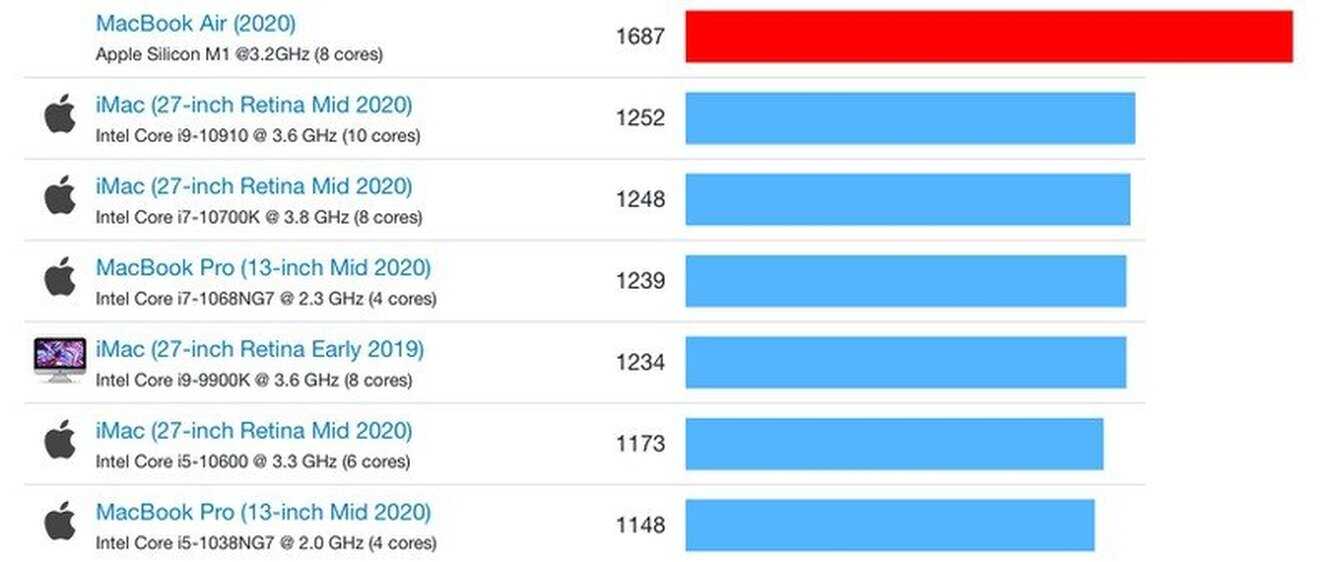
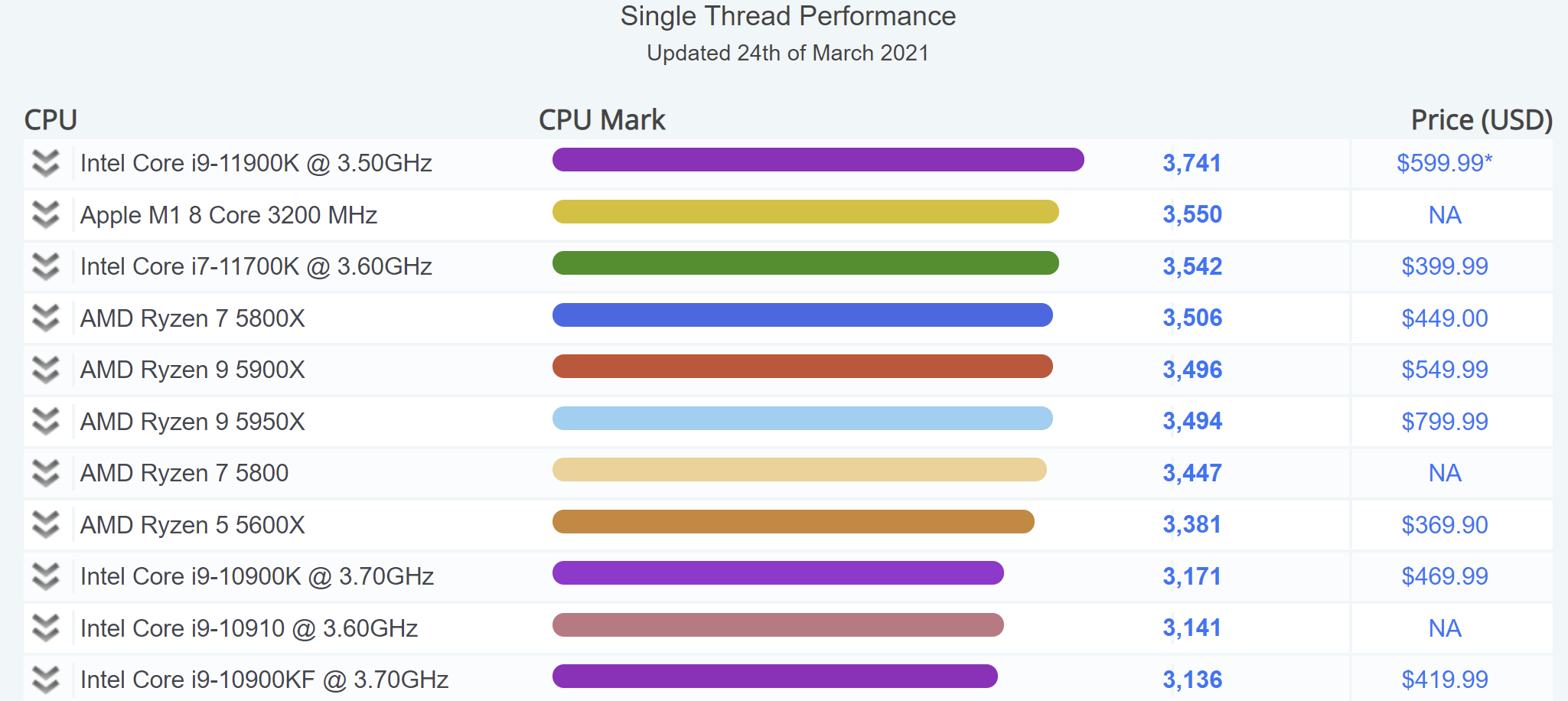
- M1 набирает до 1700-1750 баллов в однопоточном и около 7400 баллов в многопоточном тесте;
- 1700 баллов однопоточной производительности – абсолютный рекорд теста как процессоров в компьютерах Mac, так и для любых процессоров в целом. Ближайшие преследователи из других Mac – мощнейшие модели Core i7 и Core i9 в топовых iMac и MacBook Pro. Они набирают около 1250 баллов, т.е. отстают примерно на 26%;
![]()
В ассортименте Apple сейчас остаются Mac на базе как нового M1, так и Intel. Причём с прежними процессорами оставлены более дорогие модели, отличающиеся использованием до 64 ГБ ОЗУ и, в случае наиболее дорогих решений, полноценной видеокартой AMD
- В целом же среди процессоров лидерами GeekBench по однопоточной производительности до появления M1 были AMD Ryzen 9 5900X и 5950X, а также Ryzen 7 5800X, которые набирали примерно 1630 баллов;
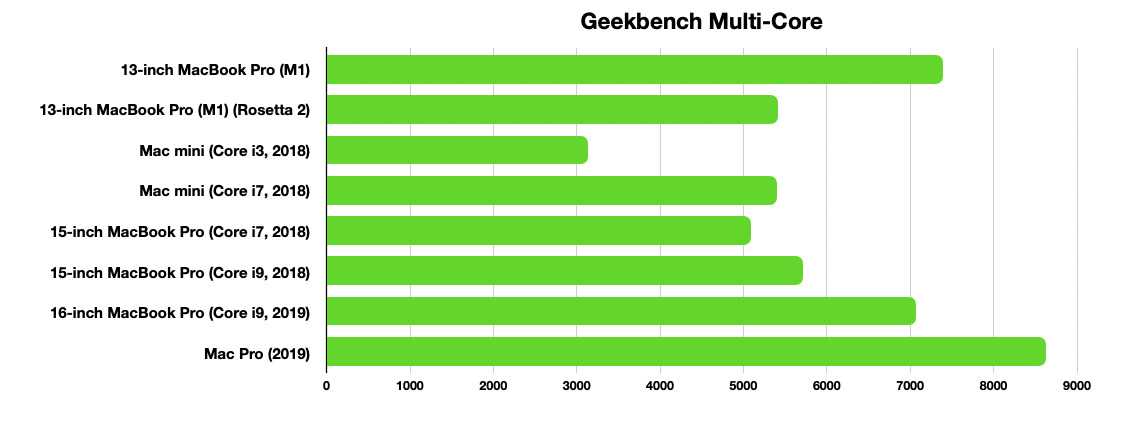
- 7400 баллов в многопоточном тестировании – не рекордный, но все равно очень сильный результат для компьютеров Mac. Больше показывают только крайне мощные модели i7, i9 и Intel Xeon в составе стационарных iMac, iMac Pro и Mac Pro. В свою очередь, M1 способен выдать результат 7400 даже в ноутбуке;
- Прежний максимум для ноутбуков Apple показывали Core i9-9980HK и Core i9-9880H, набирая в тесте 6500-6800 баллов (т.е. на 9-14% хуже).
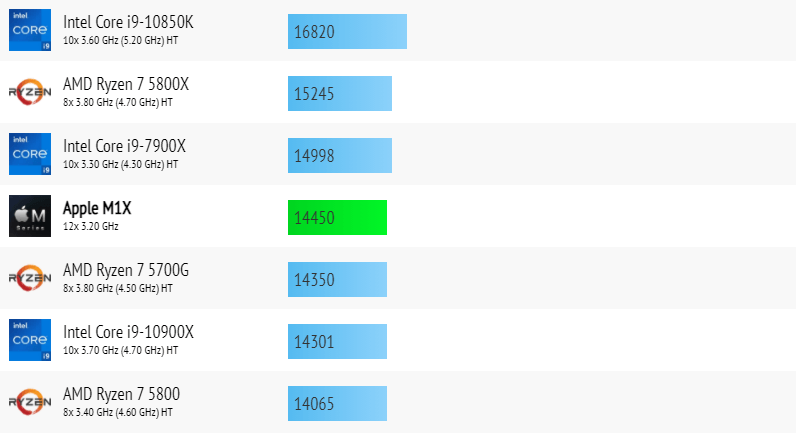
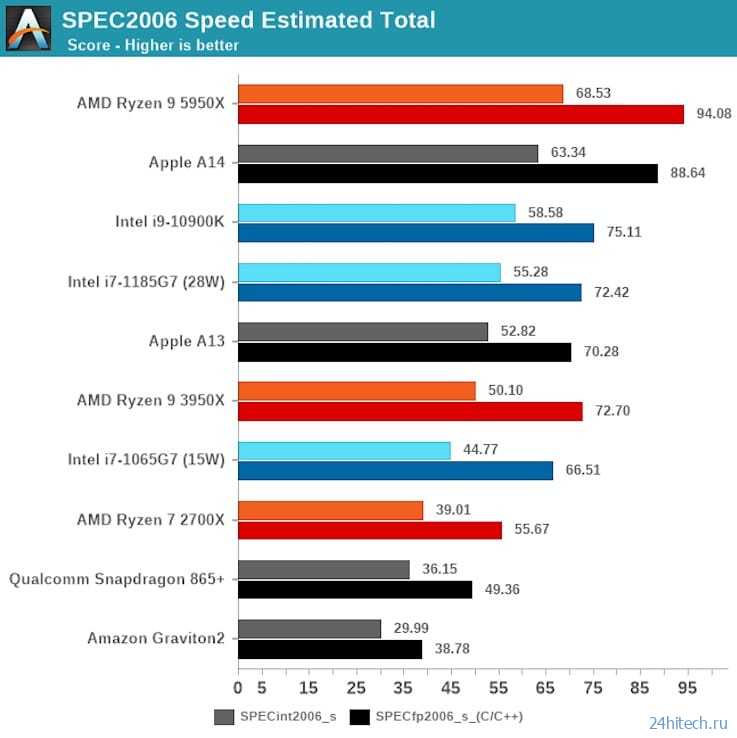
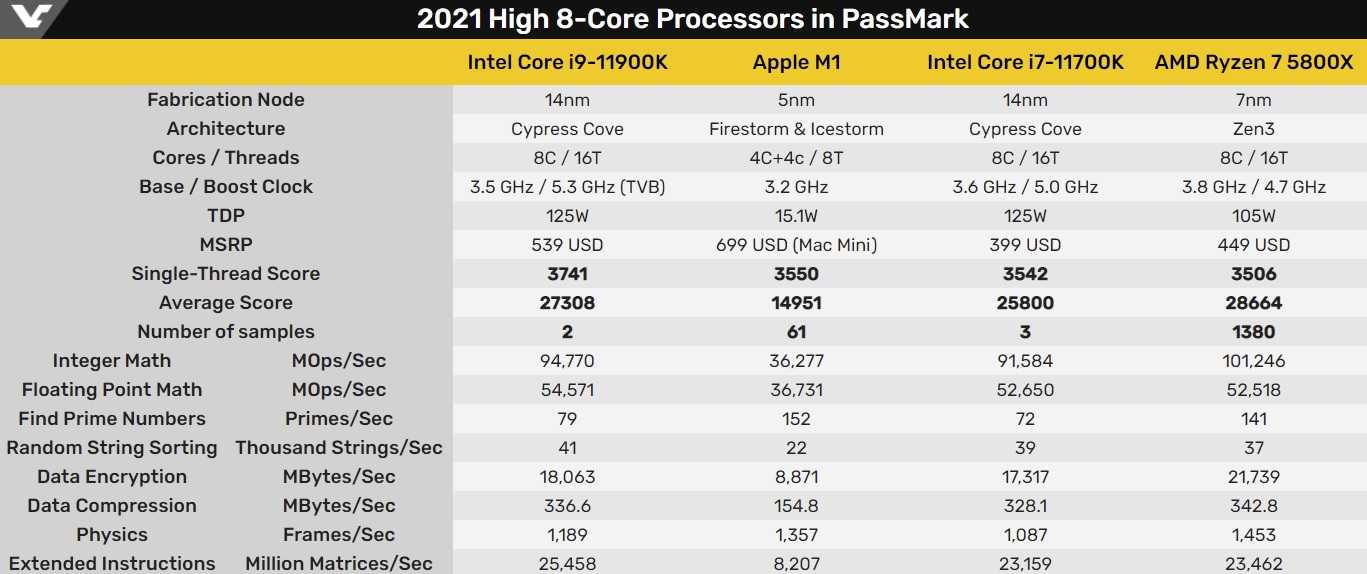
Если сравнивать M1 не только с процессорами из других компьютеров Mac, а с любыми CPU в целом, то M1 в тесте Geekbench обходит подавляющее число современных процессоров. Впереди оказываются только актуальные модели Intel Xeon, а также новые решения Intel и AMD с 8 полноценными ядрами (с частотой не менее 3 ГГц) и более.
![]()
Apple рассказывает про M1 в описании к новым MacBook Air и прочим новинкам на официальном сайте
- По сравнению AMD: M1 опережает Ryzen 5 2600, 2600X, 3600, 3600X, а также Ryzen 7 2700 и 2700X. В то же время M1 заметно уступает по производительности, к примеру, AMD Ryzen 5 5600X, Ryzen 7 3700X, 3800X, Ryzen 9 3990X, 3950X и актуальным Ryzen Threadripper;
- По сравнению с Intel: M1 опережает Core i5-9400, i5-9600K, i5-10400, i5-10400F, i5-10600, i7-9700. Выступает примерно наравне с i7-9700K. Однако M1 существенно отстаёт от Core i7-9800X, Core i9-9900, i9-9900K, i7-10700 и Core i7-10700K, Core i9-10900/10910 и более мощных процессоров, включая актуальны Intel Xeon.
![]()
M1 в ноутбуке MacBook Air
Вопрос №5: почему всем плевать на вопрос №4?
Допустим, у нас есть банк или авиакомпания, которая серьёзно решила снизить OPEX за счёт экономии на лицензиях, уходя с Xeon E5 на EPYC 2. В таких компаниях отказоустойчивость является критичной, и достигается не только за счёт резервирования средствами кластеризации, но и за счёт приложения. Это значит, что в самом простом случае, какая-нибудь там MySQL работает на двух хостах в режиме Master/Slave, а распределённая база данных NoSQL вообще допускает отвал одного из узлов без остановки своей работы. И уж здесь совсем нет проблем остановить резервный сервис, перенести его куда требуется и загрузить заново. И чем крупнее компания, чем важнее для неё отказоустойчивость, тем большую гибкость допускают её IT-ресурсы




То есть, там где к IT мы относимся как к сервису, у нас резервируется сам сервисный софт, не важно где и на какой платформе он работает: в Москве на VMware или в Никарагуа на Windows.
Совсем другое дело — облачные провайдеры типа Mail.ru, Yandex, Облакотека, Selectel… Для них продукт — это работающая виртуальная машина с аптаймом 99.99999%, и выключить клиентский ВМ ради переезда на EPYC — нонсенс. Но и они не рвут на себе волосы от отсутствия живой миграции между Intel и AMD, и дело тут в философии построения ЦОДа. В нашей статье «Секреты профессионалов: как масштабируют ЦОД облачные провайдеры» представитель компании «ИТ-Град» (входит в группу МТС) рассказал, что облачные ЦОДы строятся по принципу «кубиков», или «островков». Допустим, один «кубик» — это вычислительный кластер на абсолютно одинаковых серверах + СХД, которая его обслуживает. Внутри этого кубика происходит динамическая миграция виртуалок, но сам кластер никогда не расширяется и виртуалки с него на другой кластер не мигрируют. Естественно, что кластер, построенный на Intel, всегда и будет оставаться таким, и в одно время либо просто будет модернизирован (все серверы заменят на новые), либо утилизирован, а все ВМ переедут на другой кластер. Но апгрейды/замены конфигураций внутри «кубика» не происходят.
|
Николай Араловец, cтарший системный инженер облачного провайдера «ИТ-ГРАД» (входит в Группу МТС) • Мне видится грамотным подход к сайзингу исходя из определения «кубика» для вычислительного узла (compute node) и хранилища данных (storage node). В качестве вычислительных кубиков выбирается аппаратная платформа с определенным числом ядер CPU и заданным объёмом памяти. Исходя из особенностей платформы виртуализации делаются прикидки сколько «стандартных» VM можно запустить на одном «кубике». Из таких «кубиков» набираются кластера/пулы где могут быть размещены VM с определенными требованиями к производительности. • Базовый принцип сайзинга заключается в том, что все серверы в рамках пула ресурсов — одинаковые по мощности, соответственно и стоимость их одинакова. Виртуальные машины не мигрируют за рамки кластера, по крайней мере, при штатной эксплуатации в автоматическом режиме. |
И если захочет Cloud-провайдер сэкономить на лицензиях и вот просто на железе в пересчёте на CPU ядро, то он просто поставит отдельный «кубик» из десятка-другого серверов на AMD EPYC, настроит СХД и введёт в эксплуатацию. Так что даже для облачников не имеет значения, что клиентскую виртуальную машину нельзя перенести наживую с Intel на AMD: у них просто не возникает таких задач, и представитель VMware это подтверждает.
Братство «проца»
То, что в Olivetti отказались от идеи развивать собственную компьютерную платформу, вовсе не означало погибель для ARM. Хаузер изыскал способ выделить процессорный бизнес в отдельную компанию и нашел двух заинтересованных в этом партнеров. Объединенное предприятие назвали так же, как и архитектуру процессора, — ARM, но расшифровку сменили с Acorn RISC Machines на Advanced RISC Machines.
Кому в тот момент могло понадобиться партнерство с разработчиком процессоров RISC? Очевидно, фирме, выпускающей устройства на их основе. Ей стала Apple: там в 1990 году как раз проектировали будущий наладонник Newton, и процессор ARM отлично годился для него благодаря своей экономичности по отношению к заряду батареи.
![]() Штаб-квартира ARM в Кембридже
Штаб-квартира ARM в Кембридже
В качестве третьего партнера была выбрана фирма VLSI Technologies. Это прямая наследница VLSI Project, которая занималась проектированием и производством интегральных микросхем
Для будущего совместного предприятия было важно то, что VLSI могла предоставить собственную систему автоматизированного проектирования
Самой же VLSI был нужен новый заказчик процессоров. Это в чистом виде воплощение идеи Конвея и Мида, когда разработчик и производитель СБИС работают раздельно (а в данном случае даже находятся по разные стороны Атлантического океана). Наученный неудачей Acorn, Хаузер внес еще одну коррективу: вместо того, чтобы выпускать сам продукт, он предложил заниматься исключительно проектированием процессоров и продавать интеллектуальную собственность — то есть дизайны микросхем и лицензии на их производство.
Если Intel знаменита тем, что имеет десятки заводов по всему миру, то у ARM нет ни одного. Это не помешало сегодняшней ARM не только встать в один ряд с Intel и AMD, но и потихоньку превратиться в серьезную угрозу для них.
Сверхбольшие интегральные схемы
В то время как индустрия переживала бум домашних компьютеров, в научной части отрасли происходили другие не менее захватывающие события. Одно из них имеет непосредственное отношение к появлению ARM.
Общеизвестно, что интернет был придуман в Агентстве по перспективным оборонным научно-исследовательским разработкам США (DARPA), однако это не единственный проект DARPA, оказавший мощное влияние на всю индустрию
VLSI Project как раз из таких разработок: его относительно малая известность просто несоизмерима с его важностью. VLSI расшифровывается как Very-large-scale integration — сверхбольшая интегральная схема, или СБИС
В начале восьмидесятых все шло к переходу на такие схемы, но при их разработке инженеры столкнулись с серьезными проблемами.
С ростом числа транзисторов, умещающихся на кристалле интегральной схемы, проектировать процессоры становилось все сложнее, и, когда число транзисторов стало превышать сотню тысяч, старые методы начали приводить к появлению ошибок. Требовался новый способ проектирования, и вряд ли кого-то удивит, что решение заключалось в использовании компьютера.
Профессор Калифорнийского технологического института Карвер Мид и программист из лаборатории Xerox PARC Лин Конвей предложили создать систему автоматизированного проектирования (САПР), которая бы помогала делать процессоры фактически любой сложности. На тот момент для работы с такой программой понадобился бы суперкомпьютер, так что DARPA пришлось профинансировать не только создание САПР, но и все вокруг: разработку рабочих станций и даже операционной системы. Позднее из этих проектов вырастут фирмы Sun Microsystems и Silicon Graphics, а в качестве ОС будет создана новая ветвь UNIX — Berkley Distribution Software (BSD).
Мид и Конвей полагали, что если разработка процессоров будет лучше автоматизирована, то делать их смогут небольшие фирмы или даже студенты в ходе обучения. Идея оказалась не только верной, но и очень удачной: с помощью новых инструментов процессоры стало намного легче проектировать и появилась возможность делать это в отрыве от производства. Мало того, новый софт позволил выявить доселе скрытые особенности строения процессоров.
Технология Secure Enclave и процессор обработки изображений (ISP)
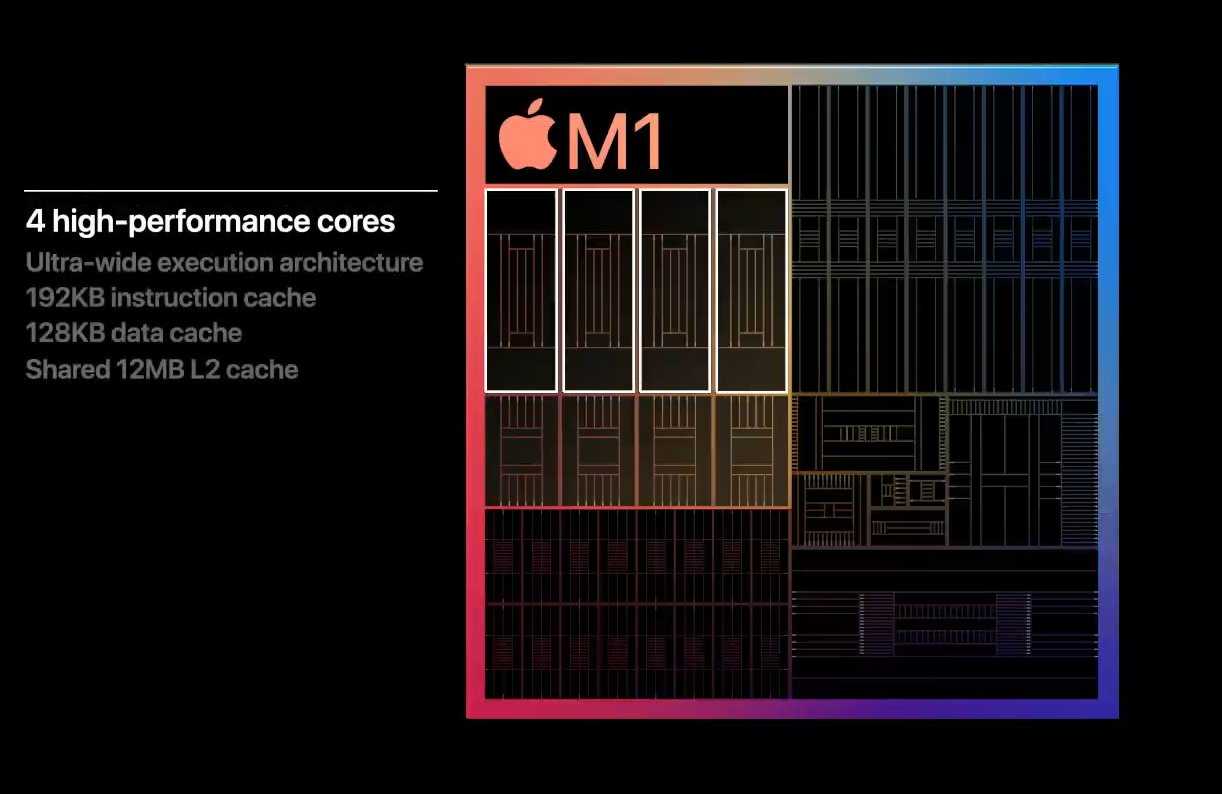
Как и ожидалось, M1 получил Apple Secure Enclave для работы с аутентификацией Touch ID и других задач безопасности. Однако это не первый случай, когда Apple презентует Secure Enclave на Mac. В предыдущих компьютерах Mac Apple включала Secure Enclave в чип T1 или T2, но теперь технология будет интегрирована непосредственно в M1.



![]()
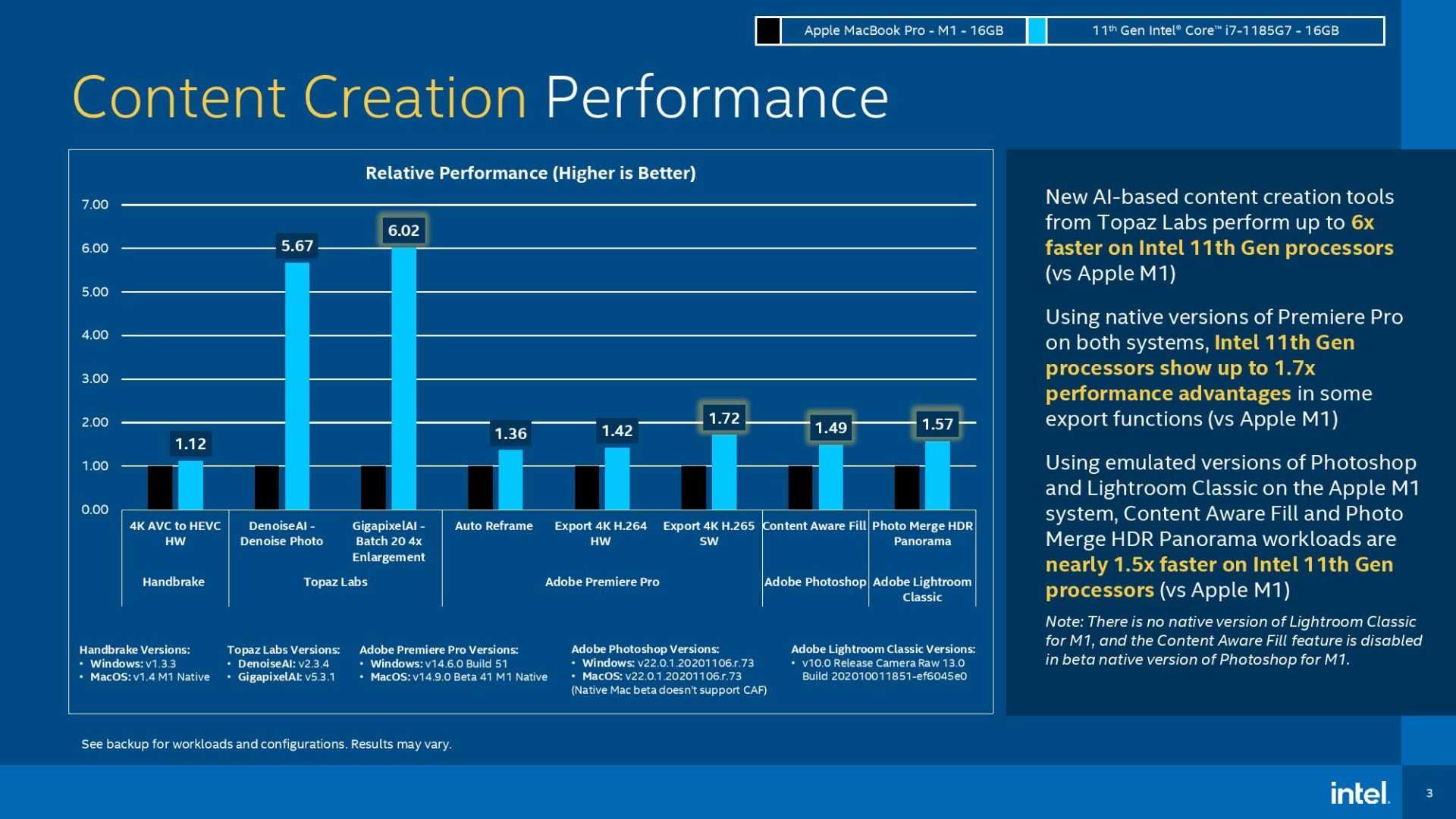
Apple также сообщает, что в чипе M1 установлен новейший процессор обработки изображений, обеспечивающий более высокое качество видео и улучшенное шумоподавление, а также улучшенный баланс белого и больший динамический диапазон. Именно это дает Apple основание заявлять, что новые MacBook Air и MacBook Pro улучшили свои веб-камеры, несмотря на сохранение ее прежнего разрешения 720p.
Графический процессор M1
Но M1 на этом не останавливается: он также оснащен 8-ядерным графическим процессором, который может одновременно работать с 25 000 потоковыми задачами. По мнению Apple это означает, что M1 может с легкостью справляться с «чрезвычайно сложными задачами». Производитель сообщил, что M1 имеет «самую быструю в мире интегрированную графику в персональном компьютере» с пропускной способностью 2,6 терафлопс.
![]()
Но что же все это даст пользователям в реальности? Больше информации появится с выходом первых компьютеров на базе Mac M1. В теории вы легко сможете играть в Apple Arcade, редактировать видео, подключать внешний дисплей с разрешением 6K и многое другое.
Оба новых MacBook Pro и Mac mini доступны исключительно с 8-ядерным графическим процессором. Новый MacBook Air выйдет с 7-ядерным или 8-ядерным вариантом графического процессора.
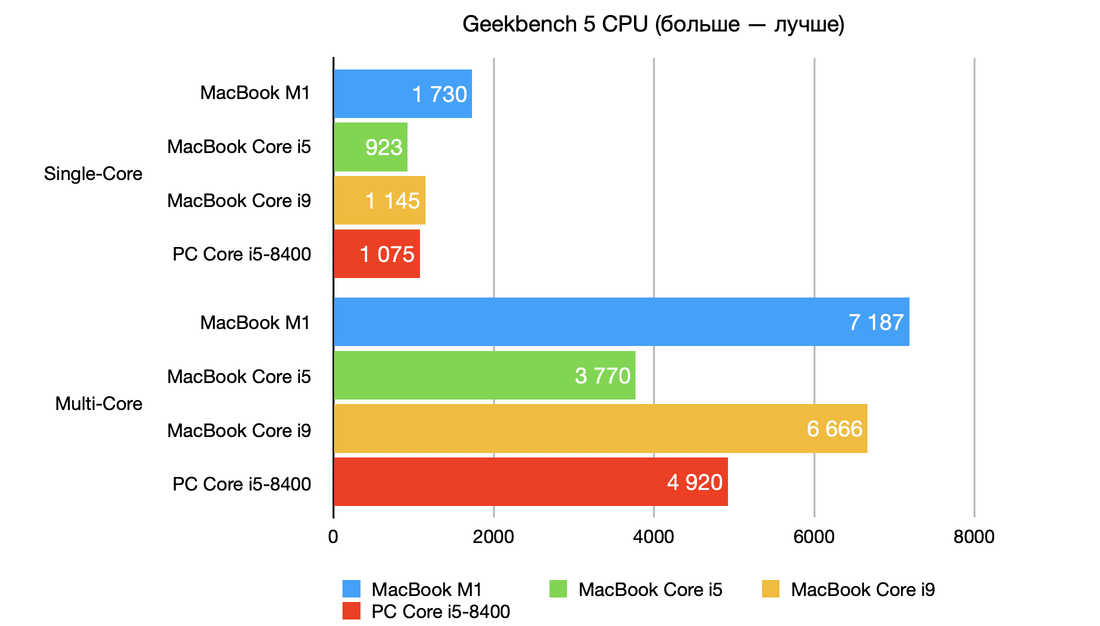
Продолжая разговор о производительности процессора M1 нельзя не упомянуть о впечатляющих результатах Geekbench теста. MacBook Air с процессором M1 обошел по производительности топовые компьютеры Apple на процессорах Intel, в том числе 16-дюймовый MacBook Pro:
![]()
![]()
Кодирование данных: Adobe Lightroom, BRAW Speed Test, HandBrake и LameXP
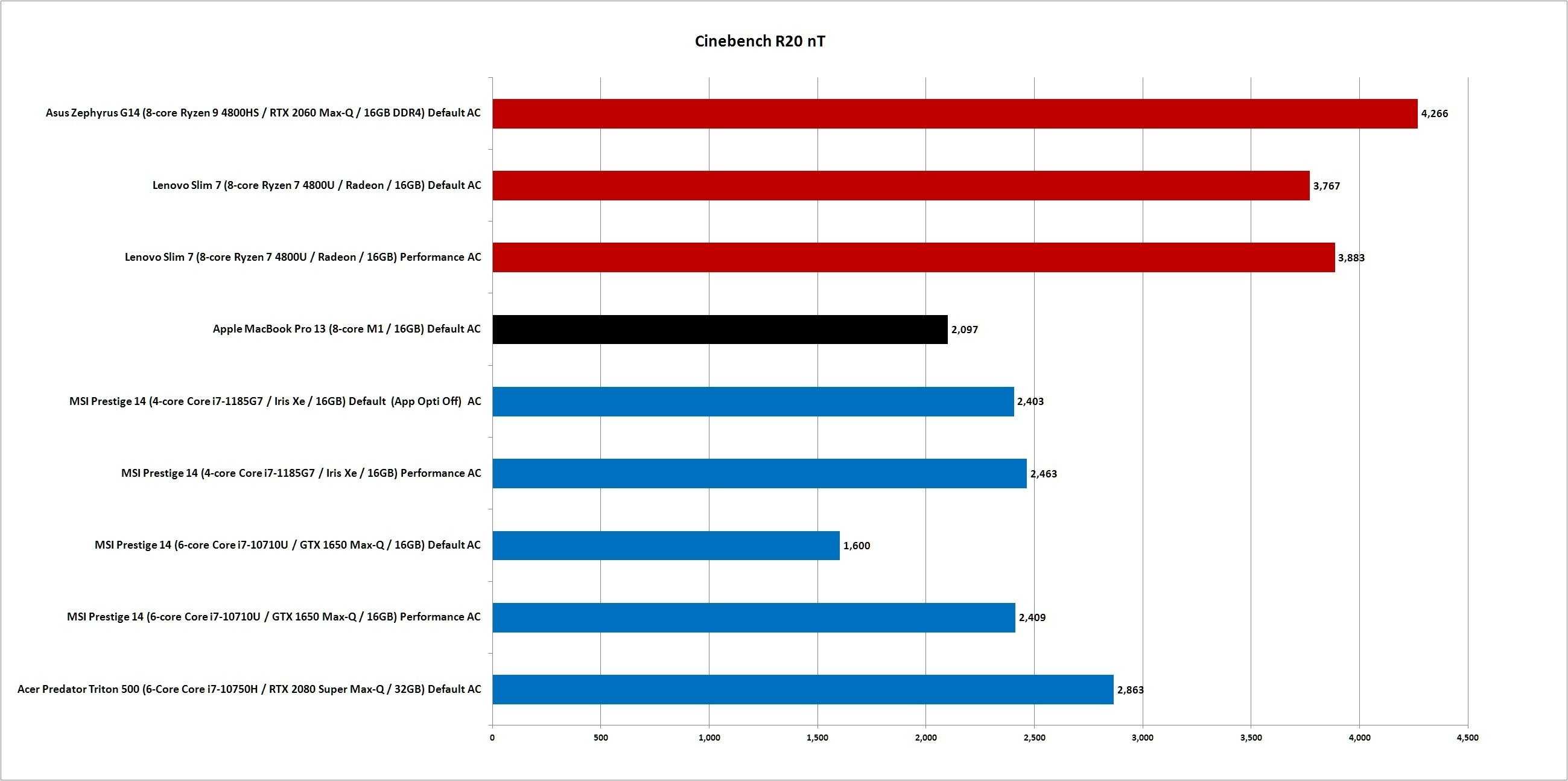
В этом разделе мы рассмотрим еще несколько примеров кодировочной нагрузки. Adobe Lightroom мы начали использовать в качестве бенчмарка сразу после его выхода, но несколько лет назад отложили его в сторону – из-за плохой оптимизации многопоточных режимов. Однако через некоторое время ситуация изменилась, и теперь это приложение на многоядерных процессорах работает вполне эффективно.
В дополнение к Lightroom, мы также провели быстрый тест Blackmagic RAW Speed Test, который наглядно показывает, как процессор справляется с воспроизведением формата BRAW при разных уровнях сжатия. Кроме того, мы провели тест в приложении LameXP – это открытый кодировщик музыкальных форматов, который использует преимущества многоядерных процессоров. Наконец, мы провели тесты в суперпопулярном кодировщике HandBrake.
Adobe Lightroom Classic
![]()
![]()
Временами даже не верится, что мы проводим тестирования в Adobe Lightroom вот уже почти 14 лет. В течение этого времени мы долго использовали одну и ту же тестовую подборку фотографий, снятых аппаратом Nikon D80. Но недавно один наш друг заметил, что подборка устарела, и обеспечил нас новым комплектом фотографий с высоким разрешением, снятых в формате RAW камерой Canon DSLR. К нашему удивлению, распределение результатов в целом сильно не изменилось, но файлы большего размера дают более интенсивную тестовую нагрузку.
До сегодняшнего дня мы тестировали в Lightroom только пересохранение исходных RAW-фотографий в формате JPG с изменением размера и матированием изображения. В этот раз мы добавили сюда тест с пересохранением RAW в DNG, и хорошо сделали, потому что, как видно из приведенных выше диаграмм, во втором тесте распределение результатов существенно отличается от первого.
В тесте с JPG чипы Threadripper заняли первые три места, а в тесте с DNG они заняли последние три места. По-видимому, перекодирование в формат DNG оптимальным образом задействует число ядер и тактовую частоту процессора, что ставит на первое место 16-ядерный чип 5950X. Забавно, что Threadripper’ы, доминировавшие в JPG, в DNG съехали в самый низ турнирной таблицы
Если вам нужен многоядерный чип, который будет эффективен в Lightroom, обратите внимание на Ryzen 9 5950X или на Core i9-10980XE.
Blackmagic RAW Speed Test
![]()
BRAW – это формат, который может в равной мере использовать мощности CPU и GPU, что подтверждают вышеприведенные результаты теста. И снова, первое место занимает не 64-ядерный 3990X, как можно было ожидать, а 32-ядерный 3970X. Но остальные результаты, кроме первых двух мест, распределились вполне ожидаемым образом. Сравнительно бюджетные модели, такие как 8-ядерный 5800X или 10-ядерный 10900K выглядят здесь довольно прилично, но более мощный процессор, конечно, будет заметно эффективнее.
HandBrake
![]()
![]()
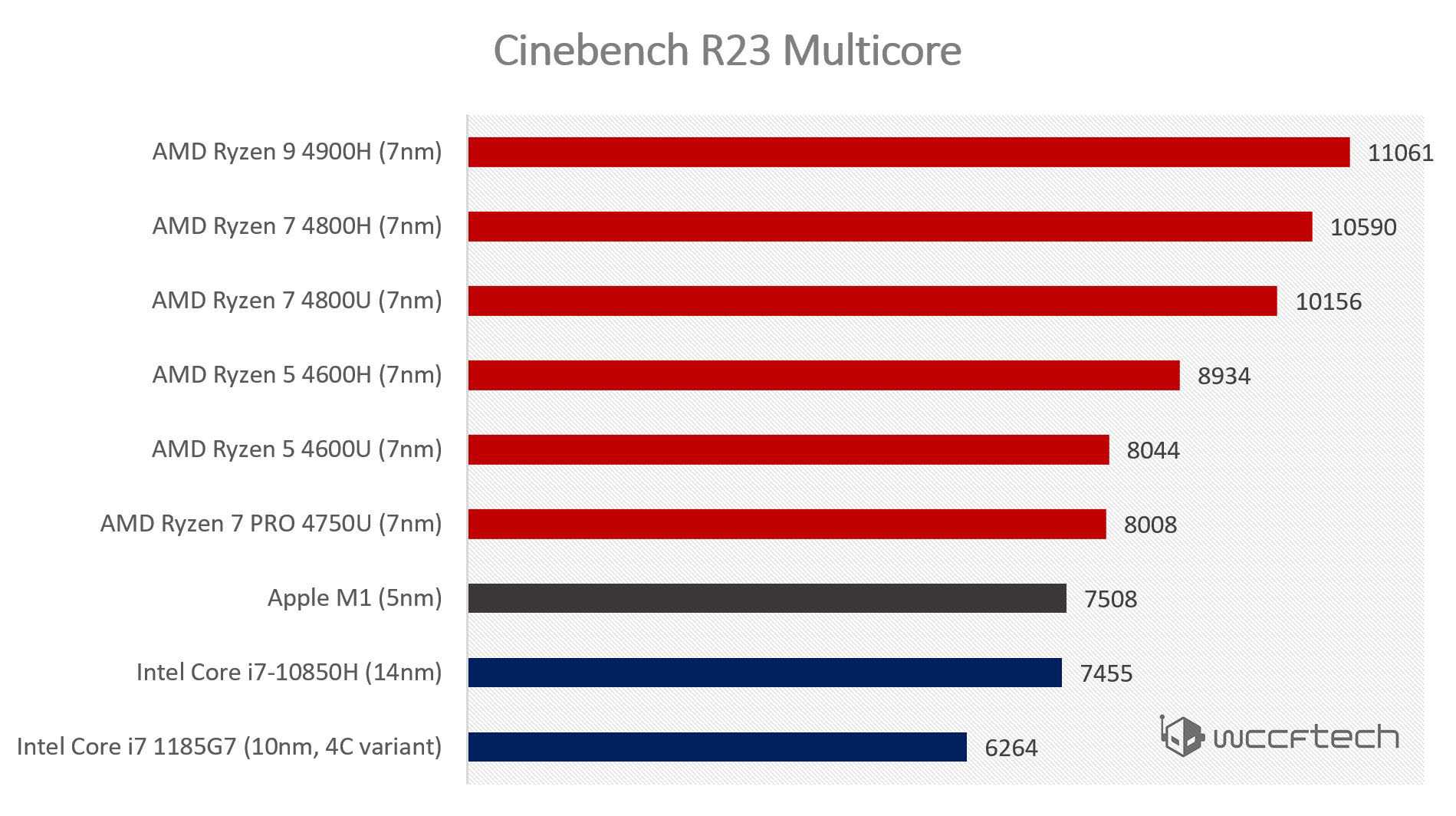
Тесты в HandBrake снова ставят на первую позицию 32-ядерный 3970X. Теперь уже практически очевидно, что, хотя 64-ядерный 3990X в своей области действительно впечатляет, большинство приложений, осуществляющих кодирование данных в различных форматах, лучше идут на более легких процессорах. И нам не терпится посмотреть, изменится ли ситуация в следующем поколении Threadripper, базирующемся на архитектуре Zen 3.
В сегодняшней тестируемой линейке процессоров наиболее выгодным вариантом за свою цену представляется 12-ядерный Ryzen 9 5900X. Он на равных конкурирует с более тяжелым 18-ядерным чипом Intel i9-10980XE.
LameXP
![]()
Как человеку, перекодировавшему за годы десятки тысяч музыкальных треков, за тестом типа LameXP мне далеко ходить не надо (даже если я больше не занимаюсь кодированием музыки в таком объеме благодаря стриминговым сервисам). LameXP задействует далеко не все вычислительные потоки, предлагаемые Threadripper’ами, но тем не менее эти процессоры смогли обойти здесь представителей массового сегмента.


Чип 5950X здесь продолжает выступать сильно, но все остальные процессоры, кроме Threadripper’ов, расположились в ожидаемом порядке. В будущем хорошо бы провести в этом приложении тест, задействующий все ядра/потоки, и посмотреть на распределение результатов. Такая нагрузка – с достаточно большим количеством рабочих потоков – также хорошо подошла бы для тестирования накопителей.
График сравнения
Одним из ключевых графиков презентации М1 было сравнение производительности решения Apple на единицу мощности относительно остальных компьютеров. Сравнение вычислительных решений – вещь неоднозначная. Apple критикуют за методику. Сравнение по случайным точкам производительности неоднозначное, но обозначенная точка для 10 Вт, в которой Apple заявляет превосходство по производительности в 2 раза относительно традиционных процессоров имеет, определенный смысл. Ведь именно такой номинальный показатель TDP (расчетная тепловая мощность, англ. «thermal design power» ) чипов, используемых в MacBook Air на базе Intel.
![]()
Опять же, именно благодаря характеристикам энергоэффективности, которых Apple смогла достичь в мобильном сегменте, M1 обещает продемонстрировать такой большой выигрыш. Картина определенно соответствует имеющимся данным по процессору A14. Другими словами, можно быть точно уверенным, что красивые кривые, нарисованные Apple для сравнения производительности чипов M1 и Intel, являются точными на всем показанном диапазоне. А выбранные крайние точки лучше всего показывают превосходство одного решения над другим.
Заявлениям Apple о производительности и энергоэффективности не хватает точного контекста, ведь трудно понять: что с чем и в каких условиях надо сравнивать. Переменных действительно много, а деталей пока откровенно не хватает. Но все это незначительные придирки к фактам, которые подтверждают преимущество даже менее мощного Apple A14 относительно чипов Intel для ПК в ряде тестов.
Acorn – начало
Шел 1979 год. Atari представила свою версию игрового автомата Asteroids. На свет появился язык программирования ADA. Основались такие компании, как 3COM, Oracle, и Seagate. TI вышла на компьютерный рынок. Hayes начала продажи своих первых модемов, которые впоследствии стали промышленным стандартом. Были представлены процессоры Motorola 68K и Intel 8088. И в это же время Герман Хаузер (Hermann Hauser) и Крис Керри (Chris Curry) с группой студентов и исследователей из различных лабораторий Кембриджского университета основали Acorn Computers, чтобы начать разработку персональных компьютеров в Кембридже.
| |
| Основатели Acorn Герман Хаузер и Крис Керри в конце 1970-х годов |
Первым продуктом Acorn стал британский домашний компьютер Atom с быстрым по тем временам процессором 1 МГц и 12 килобайтами ПЗУ и ОЗУ. После этого, в целях расширения производства и сбыта домашних компьютеров, а также, для повышения компьютерной грамотности британцев компания начала работу с Британской телерадиовещательной корпорацией (BBC). Получившийся продукт, BBC micro, достиг поразительного успеха после выхода в свет в 1982 году.
| Персональный компьютер Atom – первый продукт компании Acorn |
| Компьютер BBC micro |
Однако остальные игроки на компьютерном рынке тоже не сидели сложа руки. Например, компания Apple представила компьютер Lisa, который сочетал в себе первую для ПК коммерческую оконную среду и 16-разрядный процессор. Это дало понять людям из Acorn, что все увеличивающаяся производительность будет необходима за пределами сферы 8-разрядных вычислительных машин. И в качестве непосредственного результата в Acorn был организован отдел Перспективных исследований и разработок, чтобы попытаться реализовать специальный проект процессора с сокращенным набором команд (RISC). На тот момент эта идея была довольно-таки революционной.



